|
Please
Note:
The
following is provided for historical purposes only... Enjoy.
May
12, 1999
A
Proposal to the ESIP Federation
for
review and consideration by
The
Federation Interoperability Group
and
its subcommittees
including
The
SWIL Tiger Team
The
following proposal and its addendum(s) describe an implementation using
the BigSur Earth Science System®
for ESIP Federation interoperability purposes. The proposed system is
capable of performing earth science beyond that required to be considered
a Software Interoperability Layer (SWIL) and the beginning of the proposal
points out benefits of going beyond such requirements. Because our proposed
system is capable of functioning merely as a software interoperability
layer, and because there is presently an emphasis upon a SWIL solution
to interoperability, the system we propose should be considered for this
purpose. We have in our addendum addressed the specific proposed criteria
for a SWIL, as documented on the web page previously located at http://www.icess.ucsb.edu/~frew/ifederation/SWIL/
now archived in our SWIL files.
On
Making a Federation
of
Earth
System Information Partners
April, 1999.
The challenge of assembling
a working federation out of established researchers in related but distinct
disciplines is overcoming the cacophony of voices and individualism which
inherently exists. With the ubiquity of computing technology in research
work today, it would seem natural to use computers as a means to bring
harmony, but in scientific computing we find a plethora of solutions to
what appear to be common problems. Each researcher has their own favorite
data types and data-type hierarchies, data manipulation and visualization
tools, system architectures and research paradigms. Given tight budgets,
it is hard for individual researchers to see the benefits to them which
might offset the cost of changing their ways. And, often enough, researchers
disagree with the technical arguments of their peers. In sum, Earth system
researchers are well-educated, intelligent people who have chosen to devote
their lives to a discipline other than computer science; the information
systems they create are tailored to specific problems and are in and of
themselves are not designed to be adapted to solve the problems of others,
much less the more general problem of unifying a whole community. Yet
this is precisely the need.
To address this challenge
and create a computer based information system which binds disparate Earth
system researchers into a cohesive Federation, the system must embrace
the fundamental diversity as a feature. As an example, a user of such
a system who is interested in some type of data will wish to find:
- which
sites and which specific computer systems have collections of that type
- what scientific
functions and processes operate against the type
- to what
logical groupings that data type may belong
- what types
of data are derived from that type and what processes perform that derivation
- which
tools (software packages) are available to manipulate or visualize such
data and which are the favorites of specific researchers
- what white-papers
and web sites have been written about that data type
- who are
the individuals responsible for any and all of the above
The answers
to these questions, and many others, are stored in meta-data, without
which the entire enterprise is not possible. Yet, most systems cannot
answer these questions because they were not designed to unify a community
and too many details are left as assumptions and presumptions. The key
is to have the right meta-data, organized using the right abstractions
and using the best data storage technologies presently available.
We propose a meta-data
based system which provides the infrastructure necessary to permit research
systems to be connected using the latest technologies available in commercial
systems, facilitate collaborative interaction and access by the lay public.
A Proven System
with a Community-Orientation and an Evolutionary Strategy: The critical
need to provide a Community-Oriented approach was envisaged by
the UC Berkeley led Sequoia 2000 project team as an alternative to the
Hughes EOS-DIS strategy; Emphasis was given to creating a high-performance
earth-science system, fostering collaborative efforts with distributed
processing, sophisticated searching, and strong scientific-defensibility
features, with an initial focus in geology, hydrology, oceanography, and
climate modeling. A prototype was built by the BigSur project team, and
additional diverse data-sets were included to address end-user needs such
as those of the State of California’s Resources Agency. The technology
was demonstrated as early as the spring of ’95. In the interim the
technology was commercialized in 1997, has undergone further development
by Science Tools corporation, and is performing production work at various
research centers today. We call this the BigSur Earth Science System
(or just BigSur).The most recent Evolution pushes
this paradigm even further, adding the concepts of research sites (not
just individual computers) and the publishing of materials between sites.
Adaptive-Orientation:
An Adaptive-Orientation converts diversity into an asset to
be exploited rather than a hindrance to cohesion by learning the features
of each researcher’s existing system in a direct way. The goal
is not to replace existing systems, but to harness them as tools.
For the individual researcher, an Adaptive-Orientation permits
the system to learn the ways of the researcher rather than force the researcher
to learn the ways of the system. And the system does not chase every new
advancement in data access methods, such as new HDF formats, but rather
it "learns" (or absorbs) those favored by the researcher as
they are introduced. Because of our systems Adaptive-Orientation,
it will dove-tail nicely with the DODS system and the proposed Mercury
system, and will most likely live in harmony and cooperation with any
other systems in the community.
Progressive-Utilization:
Progressive-Utilization, permits users to pick and
choose features as desired. Progressive-Utilization extends
flexibility by focusing on what the researcher finds appropriate, while
minimizing requisite burdens. While the BigSur Earth Science System
was designed to manage Earth-system data from satellite to end-user desktop,
Progressive-Utilization permits it to act as merely an electronic
notebook, or just a distributed processing system, if that’s all
that is desired.
Database-Centrism:
Of primary interest to those wishing to create a computer based federated
research information system are issues of meta-data management. Without
meta-data, sharing data is not possible; to facilitate fast, reliable,
easy and ubiquitous meta-data access, a competent database system is a
requisite core technology. The most capable system must take advantage
of the fastest, most flexible and modern data management technology available,
with as little demand for programming services as possible and a maximum
ability to accept data-requests from applications of all varieties. Therefore,
the system should be database-centric. BigSur is database-centric
and all meta-data is accessible through SQL to virtually all application
programming environments.
Meta-Data Management:
Researchers create meta-data as they perform their work, such as the type-hierarchies
and functional processes in which research methods and paradigms are implemented.
These meta-data fall into three categories: those which are "static",
such as who researchers are, those which relate directly to individual
data-objects, and those which are embedded as assumptions and presumptions
into the information systems and application programs used. Exposing these
data to others is vital. Because of the plethora of research data-types,
tools, et cetera, within the community and the changing nature of these
features over time, the system must be flexible, Community and
Adaptively-Oriented and capable of learning. Thus, BigSur
does not try to embed knowledge of these features, but rather learns (or
absorbs) those favored by the researcher, and is free to pick up new advancements,
such as HDF5. What are assumed relationships in other systems are explicitly
stated in BigSur. (For example the type-hierarchy created when
a "REGIS Aerial Photograph" is stored as a GIF file is not assumed
or implied and is instead taught to the system by making an entry associating
the two object types. Thus an object may be of type "REGIS Aerial
Photograph" and of type GIF, both at the same time.)
By applying our Adaptive-Orientation
to all aspects of meta-data, and by not locking the researcher into predefined
or rigid hierarchies, the system has deeply intimate knowledge and record
of most all aspects of scientific inquiry in its purview. Notable among
these are lineage details about each individual scientific object, all
the types and collections to which each belongs, the processes that created
them and the parental input objects to those processes. Site-specific
information is fully integrated with both data-objects and scientific
processes, so object lineage can be maintained when a researcher uses
as input data from a collaborator at another site. This permits strong
scientific defensibility of conclusions reached through collaborative
efforts throughout the community, regardless of where particular data-sets
may be stored or meta-data managed.
BigSur
can bring together and manage just the right kind of meta-data and
make a reality the promise of a cohesive Federation information system.
A High-Performance,
Distributed, Scaleable Architecture: Site-independence of data-objects
from meta-data provides a natural ability to cooperate in a distributed
environment, and provide for sharing of workload between systems. BigSur’s
Distributed Processing System permits Scientific functions to be performed
on any system in the network, as desired, with both process-level and
system-level controls for operations staff to manage workload. While BigSur
can be implemented on any ORDBMS, use of the Informix Universal Server
permits the use of their R-Tree index structure, providing the fastest
Geo-Spatial searches presently available in the commercial marketplace.
And use of modern ORDBMSs brings the benefit of robust tools for managing
a site.
Putting
it all together
The system can be
installed and put to immediate use. Some software needs to be written,
primarily a web-based application tailored to browse the Federations collections,
and the various means by which existing data will be made available to
BigSur. To facilitate collection of meta-data, each ESIP must designate
a technical liaison to assist others in obtaining their meta-data for
collective purposes in an ongoing way.
Obtaining meta-data:
The meta-data for
a site can be managed by another site – doing so is rather trivial
as long as a strategy is implemented to keep the meta-data up to date
– the location of the meta-data is irrelevant. In this way a small,
resource-poor site can be "hosted" elsewhere.
Configuration options
for a Federation information system include the use of a single "master"
repository, distributed databases at each (or most) site(s), or a combination
of these. The present system is capable of any of these choices and even
includes a "publishing" mechanism by which meta-data managed
at a remote site can be kept current automatically.
For those that wish
to use BigSur’s Distributed Processing System, the system
can automate meta-data update and perform publishing to a central ESIP
site, if one is used. Process-scripts must be written which manage scientific
processes, update the meta-data, and perform publishing between sites.
These scripts may be written by our staff, by representatives at each
site, or by the collaborative effort of both. There are existing scripts
and templates to illustrate the way, and there is a Java language Application
Programming Interface library available.
If researchers prefer
to continue to use their existing systems, or use BigSur but manually
run their scientific functions, another means must be devised to insert
meta-data for any new objects created. Such meta-data may be inserted
manually. An addition to an existing system could automate insertion of
meta-data into BigSur. These new objects could be observed and
have their meta-data populated by an as yet unwritten program that updates
a central database much as web search engines utilize a ‘web-crawler’
to discover otherwise unknown web pages. Or, similar to the web- crawler
approach, a "gateway" could be written to access meta-data stored
in another information management system. The key is to have a mechanism
which captures the maximum information available.
An ESIP-specific
Application: An application should be written oriented primarily
toward non-Federation members such as non-Federation researchers, "K-12",
the public at large, and the occasional Senator. Because the underlying
tool is a modern database engine, simple SQL ad-hoc queries can suffice
for many Federation users, and a host of application development tools
are available for those who wish to do their own interesting things. A
general-purpose, public-at-large application with a web interface can
easily be written because of the many tools available from the commercial
market place for SQL compliant databases. In addition, the BigSur Earth
Science System includes a programming tool-kit in the form of a Java
API.
We
propose
the installation of a Federation database to be managed by the ESIP Federation,
perhaps at the Federation’s Web Page providers site. Into that database,
each member site will be represented. We can then populate it nearly immediately
with a basic outline of what each ESIP member does. Tangible results can
therefore be obtained very quickly during system implementation –
nearly immediately. For each ESIP member, a long-term method of ingesting
meta-data into the database must then be devised and this will vary with
each site as the present means of storing this data also varies. The exact
scale of this work is not known at this time, but at least a moderate
level of meta-data should be fairly easily ingested. Each site will have
a base minimum of data populated into the system and as much as can "easily
and quickly" be done to permanently solve the meta-data ingestion
strategy at each site will be worked out and implemented as fully as possible.
And, an application will be authored to permit browsing of the assembled
meta-data with an ESIP Federation focus as described above.
The Federation Web
Site has not yet been codified nor the systems for it secured, and no
one can yet realistically state what kinds of workload demands will be
made of Federation-unifying systems. Authoring of an application for ESIP
browsing is surely a never ending development effort, and the man-hours
required to evaluate existing meta-data storage techniques and implement
a collection strategy for each is clearly not small. Available funding
is limited toward these efforts and realistically we know that there is
simply not enough money to fund all that one might wish to do.
We therefore propose
the modest sum of $X per year to fund the above outlined activities. We
believe this to be sufficient to obtain fundamental goals. Should a Federation
Web-Site provider be willing to participate in our efforts, we may move
forward at an accelerated rate. And with designated liaisons at each ESIP
members site, we may move forward at an even greater rate.
Richard Troy,
Chief Scientist
Science
Tools Corporation,
1345
Wicklow Lane, Ormond Beach, FL 32174
ScienceTools.com,
386-868-3846
On
Making a Federation
of
Earth
Science Information Partners
A
Proposal for Using the "BigSur"
System
Addendum
'A'
Evaluation
using
the proposed
Interoperability
Criteria and Requirement
This document is in
direct response to the criteria proposed in the "System Concept Evaluation
Criteria" presentation which was previously
located at http://www.icess.ucsb.edu/~frew/ifederation/SWIL/
now archived in our SWIL files.
We have followed the
general outline offered there. In responding, we were asked to describe
how the proposed system addresses the criteria both qualitatively
and quantitatively and what our view of any minimum levels of compliance
is.
For the
purposes of our proposal, our focus is the use of the BigSur Earth
Science System®
as a "Catalog based Interoperability system" focused on management and
browsing of the meta-data which describes the holdings of ESIP Federation
members by various user groups via the Internet. The further capabilities
of this system's use for more robust interoperability and other scientific
purposes represent an opportunity for further benefit of acceptance of
our proposal, beyond the immediate goals at hand. It is worth bearing
in mind that "catalog interoperability" is truly a minimum beginning to
interoperability, and perhaps is better described as a "common results
cataloging and browsing effort." Our system affords a valuable opportunity
for robust interoperability because of the rich suite of meta-data easily
accessible within. With its ability to intricately manage the myriad web
of relationships between objects, scientific functions, and the environments
that create them, and its ability to be progressively utilized for performing
science, researchers may directly associate the meta-data describing their
work with that of others found through the system. As more lineage meta-data
is known about the creation of derived data products, scientific defensibility
is enhanced for ESIP Members.
BigSur conforms to
the FGDC Geo-spatial meta-data standard, and has the structure necessary
to manage all meta-data common to all ESIP data. By collecting meta-data
for each ESIP Member's holdings, our solution permits individual queries
to be made literally of the whole of ESIP Members' holdings. Thus, the
system makes the Federation's disparate members appear as one entity to
browsers. Because access will be made through the Internet, the whole
of the public will be afforded access. Should an ESIP member also put
its data holdings on Internet-accessible storage media, our solution offers
direct access to the fundamental means of data-access that makes discovery
via meta-data meaningful.
While more powerful
mechanisms for populating such a database are also a part of our solution,
a fundamental foundation for doing so is the Global Change Master Directory.
Beyond using the GCMD to populate our database, we will work with other
ESIP Members to take advantage of available alternative mechanisms to
gather more robust meta-data.
Overall
criteria
- Allow
single, multiple, or composite solutions: Our
proposed solution supports other interoperability mechanisms easily
because BigSur already incorporates a mechanism for managing the meta-data
about tools existing at other sites. New and novel hand-offs between
data management tools are greatly aided by such meta-data. Our proposed
system goes well beyond this criterion.
- Multiple
must be equivalent - All the ESIPs, all the meta-data:
Because our system will manage its own copy of all of the meta-data,
and because the GCMD provides a baseline for acquiring this data from
all ESIP members, our proposal meets this criterion. We also propose
to do more, as funds allow, to help all ESIPs provide as much meta-data
as is practically possible.
- Composite;
should be seamless and "functionally equivalent":
Please see the bullet item above which addresses this.
- Security
and access control; Expose subsets of catalog information [to public]:
Our system manages meta-data identifying individual users and has a
flexible security scheme. (It also manages the meta-data for multiple
access methods into other {possibly non-BigSur} sites for varying levels
of access between systems for robust composite-solutions.) It will be
very easy to control access as desired.
Note
that at this time, it's not clear that security features are necessary
as ESIP members can control what information they publish in this
system. Therefore, there will be a natural security mechanism created
by ESIP members as they decide what to make public.
- Use
of compliance with any relevant standards;
Applicable standards fall into a few categories. For meta-data storage,
our system presently complies with the FGDC Geo-Spatial meta-data standard,
and the similar SAIF standard. We will also ensure that it does in fact
manage all data in accordance with the GCMD. This past spring (1999)
we began the addition of Z39.50 and XML servers to our system, developed
by our partner Dr. Konstantinos Kalpakis (USRA ESIP). As a database-centric
system, it naturally complies with SQL92 (the current Standard Query
Language standard), and our favored database vendor also provides us
with ODBC and JDBC for remote (internet and intranet) application connections
in Java, C, Basic, et cetera.
- Discovery
and description of services as well as data products;
We propose to directly tie in to the ESIPFED.ORG web site for user discovery
and description of our service. Once a user has discovered our service
they will then be given the opportunity to search the holdings in our
database, as well as get help regarding the services our application(s)
provide. For scientific holdings, ESIP Members must provide descriptions
they wish presented, though our proposal also includes an effort to
collect this information on their behalf. Within the database, there
will be both high level and detailed descriptions of data products and
any services available at ESIP Member sites, including descriptions
of other search tools and value-added features which may be provided
by others for obtaining, browsing, visualizing or otherwise handling
scientific data. Additionally, our system associates scientific objects
and processes with links (primarily URLs) to other relevant supplemental
information as provided by ESIP Members or as otherwise available and
known to us; for example, to document chosen vocabularies.
- Risks
- Maturity:
The
BigSur Earth Science System®
is now over two years old, and will have been in service at an ESIP
Member site (LaRC) for two years this September. The database design
is mature and solid, and is continually being improved. In our proposal,
what's new is an ESIP Federation-specific application which will
present public ESIP Member assets to Internet users. New tools will
be written to populate and maintain the database from ESIP member
holdings. The foundational technologies are all mature.
Further
reducing risk is the great compatibility between our system
and that of others. Additionally, two ESIP sites already use
our system, LaRC, and OceanESIP. The ESSW ESIP (Santa Barbara)
has an architecture which appears to be based on early University
BigSur research. We anticipate relatively easy interchange of
data with other systems used by the Federation.
- Acceptance
by users and by providers: Of
the two ESIP Members who use this system already, both endorse this
proposal and state that they prefer this approach. The Deputy Director
of the LaRC DAAC, Richard McGinnis, when asked about this system
replied, "It does everything [the designer] Richard said it would
do." Wisdom reminds us "the best predictor of the future is the
past."
- Support:
Support
must exist at many different levels: the site where the host hardware
resides, the computer(s) and operating system(s), the database product,
network interconnectivity, the application(s), and of course BigSur
itself. Each must have a support plan and be funded appropriately.
Our proposal requests that the host computer(s) for the database
system and associated infrastructure initially be managed, in the
first funding cycle, by the site which also manages the 'ESIPFED.org'
web site. Furthermore, commitments for the first year of host resources,
the above-mentioned support, and all necessary database administration
and application services have been made by both JPL's OceanESIP
project, and Berkeley Earth Science Tools Corporation.
- Technological
change:
- Continuing
support for obsolete technologies: A
key observation our architecture reflects is that in doing Earth
Science, most researchers already have existing systems. Therefore,
BigSur has an Adaptive-Orientation that allows
it to learn and adapt to an existing environments' methods,
structures, and paradigms. For example, our system has embedded
within it an ability to execute any existing code which can
be initiated from a command line, and it can store source code
and compile it on the fly, if desired. This technical ability
is illustrative of our architectural perspective.
- Migration
to newer technologies: We
have anticipated new technologies and have taken great care
to avoid embedding into our work anything which might become
stale, such as access methods. This was precisely the impetus
for the decision to develop components which permit the system
to recognize and call (at an executable level) other tool sets,
such as visualization or data access tools. Thus, technologies
that change with time are easily supplanted by new ones. The
bedrock of our system, the Relational Database System, is here
to stay for the foreseeable future.
Accessing
the Federation via a BigSur Installation – The Users View
When reviewing the
abilities of our proposed system, it may be helpful to have a perspective
on user access to the system. Access to the ESIP BigSur installation can
be accomplished in many ways:
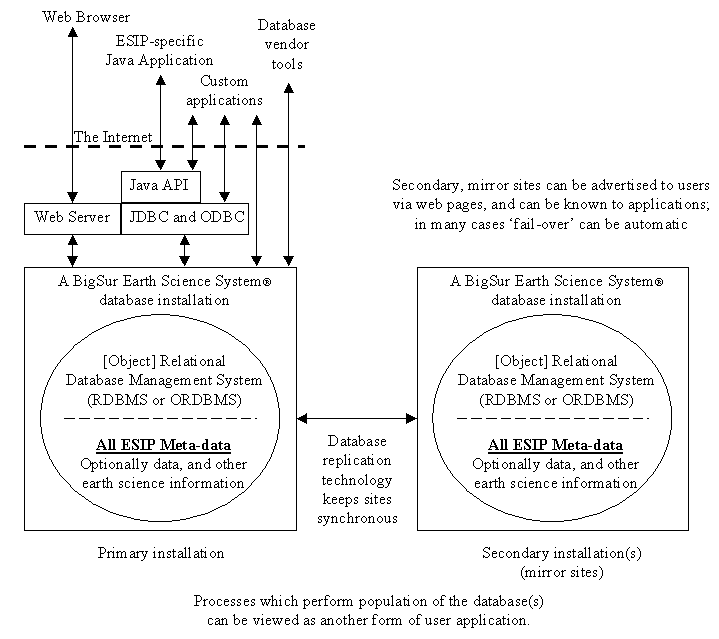
Catalog
Interoperability Criteria
The following
topics will be discussed in detail:
- Discovery / search
- Browse
- Logical data model
- User interface
- Local extensibility
- Technology
- Scalability / Bottlenecks
- Costs
- Compatibility
Discovery
and Search
Searches and subsequent
discovery are the reasons such a system is desired. We see the plain-vanilla
web-browser as the most basic common access method users will employ.
We also feel that users will desire a stateful application which will
provide quicker, more robust access. There will be those advanced users
who wish the direct power of the system to be at their command. Furthermore,
there will be different classes of users, each of which has different
perspectives on the use of the data and each brings differing levels of
knowledge with them as they sit down and perform searches. For example,
the K-12 user might inquire about wetlands. A researcher may know explicit
names of data-sets, investigations, or data-types and might wish to inquire
about them by name. A Senator may be interested in discovering what types
of data-products are created by a specific facility. Our plan address
all three types of access (HTML, application, and direct), and at least
all three of these identifiable classes of user.
For web-browser access,
our system will offer a forms-based approach that will essentially let
users form successively more specific queries. We will provide slightly
differing interfaces for the various types of users we identify in order
to assist them in forming their queries more quickly and accurately. A
Java-based application will be available for users. It will be very similar
in form to the HTML approach, but will have more capabilities, though
we plan to keep the two very close in ability. For advanced users who
wish, we will offer direct access the database via ODBC or JDBC using
either their favorite database access tool (of which there are many very
good ones on the market), or they may use one we provide. In this way,
the system can immediately be used for very sophisticated searches. Further,
developers of existing systems, such as DIAL, may wish to make the few
modifications necessary in their code lines to enable their toolsets to
browse all ESIP Federation data via BigSur, thus enhancing the value of
their own tools. (We will make a JDBC toolkit available to aid them.)
- Specificity
-Collections and Granules: Our system has
robust abilities to form and manage sets of data. Therefore "collections"
and "granules" are equally easy to find. We do this by using basic relational
database technology for defining relationships - one only need issue
the correct query to gather all the components of a collection, or to
exclude collections from a result. Our code will issue these queries
for our application's users, and from within our Java API.
- Retrieval
capabilities - Ranking, Relevance, and extent of search compliance:
Ranking, relevance and search compliance are concepts valuable to retrieval
when one asks for multiple result sets simultaneously and then attempts
to merge them, when there may be multiple names for a given searchable
attribute, or perhaps when one uses fuzzy logic. We plan to help the
user form queries which are likely to return small, appropriate result-sets,
thereby ultimately bring the same final results but without need for
these concepts. All results that return rows should be what the user
requested. To aid the user in asking for what they want, wherever possible
we will provide lists of valid search criteria. For searches which might
return a large result-set, we will first check the number of items that
satisfy a particular query and if the number is excessive, give users
the opportunity to further restrict their queries in hopes of obtaining
just what they are after.
- Search
capabilities - Geospatial ("bounding-box" - including Z),
"Fielded search", Free text, Temporal, and Common vs. local
attributes: The
BigSur Earth Science System®
is naturally capable of Geospatial queries. Our preferred database vendor,
Informix, has the world's fastest (non-static) indexing method for geospatial
attributes - the R-Tree. Both retrievals and inserts of new entries
are fast. Our design will accept single point, "bounding box," or polygonal
descriptions of geospatial location. For Z, we can use their Geodetic
Datablade. (Note that BigSur has no dependencies on Informix; it just
has important advantages.)
Similarly,
because it's founded upon a commercial ORDBMS, and because these
are simple attributes, our system easily handles "fielded search,"
free text and temporal searches. Our design incorporates keyword
and thesaurus tables, and accepts URL "pointers" to other web sites
for more in-depth descriptive information. Thus, the user is afforded
a direct interconnection between their items of interest and the
whole of resources available on the Internet. If better performance
with "free text" searches is desired, Informix also offers a Text-Datablade.
BigSur
handles common attributes as a natural part of its design. But for
those features which are unique to a given ESIP Members' holdings,
we offer two mechanisms for storing and searching these data within
our system. The basic method we use is to store such data in the
supplemental information attribute of each managed object or archetype,
as appropriate. The second, more sophisticated approach is for each
data provider making "local attributes" available to supply such
data in their own tables as extensions to the database design. In
this way, the exactly correct design which suits these unique features
may be provided. For sophisticated users, access is not a problem
as basic database tools immediately make this information available.
For a "canned application" to provide "general purpose" ability
to access these data is a bit more problematic. It is possible to
take source code intended for use in database management tools and
co-opt it for use in such an application; however, the funding we
request in our proposal is not sufficient to cover the costs of
doing so now. This can be a future add-on. A half-way approach is
viable now in which the extensions are described and the sophisticated
user directly connects.
For
access to local attributes managed in their original environments,
our system provides storage of the meta-data required for ODBC,
or JDBC access. Also stored are meta-data concerning what tools
exist to manipulate such data, and, when available, the details
of how to launch such tools.
Browse
- Specificity, by collection (e.g. coverage summaries) and by granule
Options; Static or On-Demand:
Our design incorporates
a browse table that manages "browse" copies of objects, when they are
provided. These might be of a reduced granularity or scale, or whatever
is deemed appropriate by the owner of the holdings so referenced. Such
browse data may be of granules, or collections, as available. They may
be provided to the user whenever desired - the selection criteria only
need ask for the browse copy, should one exist (i.e. this is a subset
of search capabilities).
The question
of static or on-demand browse object is an interesting one. Our system
is capable of generating new objects on request, and to do this, one would
simply provide the correct function and its arguments and submit it (via
the BigSur Distributed Processing System®).
Provided functions that create browse-objects for data-types held in our
collection, BigSur may easily create such objects on demand.
Logical
data model
- Vocabularies
- Valids / Domains, Use applicable standards: As
described above, our system provides keyword and thesaurus tables that
associate keywords and their definitions with objects. It also contains
a scientific domain table which associates keywords and domains, and
can provide a reference to what is considered valid in a given scientific
domain.
Because
we expect our data to come from ESIP Members, we feel that the issue
of deciding what keywords are valid is one for the whole Federation,
or individual ESIP Members to decide. We are ready today to accept
and implement any such decisions. In short, we feel that deciding
what keywords are valid is outside our purview.
We
feel our job is to aid users who wish to search the collection in
finding their desired data. For this, we prefer to use list-boxes
of choices for "valid vocabulary" at specific points, and to provide
aids in "translation" among vocabularies so that queries search
against actual values, whatever they may be, helping ensure that
users find the data they are seeking.
- Relationships
- Inter-attribute, Parent-child, Thesauri, and Other TBD:
We
feel that relationships are one of the very most important aspects
in the entire enterprise.
It
is especially crucial for those not familiar with data-sets and
the environment from which they come to be able to determine how
things are related. There are parent-child relationships among data,
sets, subsets, and scientific processes, and many relationships
among investigations, platforms (such as satellites), and instruments
that collect data, all of which supports performance of science
and provides the context for scientific interoperability with peers.
All of these relationships bear representation within a database
which purports to manage the holdings of the Federation. There are
further relationships also of interest, such as those in support
of the mechanics of data product generation, access, a security
scheme, and so forth. The BigSur Earth Science System® manages
all these relationships.
Our
proposed system contains associative relationships through use of
a relational database engine, and elegant database design. With
our database schema, it is easy to associate the components of an
investigation, the sensors of a satellite, and the products derived
therefrom. It's simple, for example, to inquire about what types
of data exist that were derived from data collected by a particular
instrument. These associative relationships also pertain to people
- for example, to discover what items result from the work of a
particular person or team. It is through examination of these relationships
- i.e. their availability for inquiry - that "interoperability"
becomes more than just a buzz-word.
In
our system, these relationships are explicitly managed. Parental
data sets are referenced by each child object, when this information
is available. Collections of objects are associated explicitly,
and objects may belong to multiple sets simultaneously. Our schema
does not impose a hierarchy, though it's simple to represent one.
Further, when available to us, processing lineage is also managed,
so that one can easily discover what scientific process created
a given object or set of objects. In fact, the execution of a scientific
process itself may be managed as an object, so that the results
therefrom can conveniently be represented as a whole, whether or
not they are proper "collections," or "granules." Thus, objects
in our system have three possible "parents" explicitly managed:
the archetypal description of the scientific function that created
the object, the data that was used as input to that function, and
the specific instance of that function's execution.
Because
an "object" may represent a set of objects, our system permits full
association of sets and objects in any manner desired. (This is
done by creating an object entry for the set, and then associating
set members with the set object.) Our system goes further. It associates
objects with sites; it is convenient and easy to relate an object
to the site where it was created, and the site where it is held,
should they be different. This reference can include sufficient
meta-data to provide a means of data access for such objects as
well, should access to the actual objet be desired.
Our
system also manages the relationships between types. For example,
researcher V. Zlotnicki might have a favorite encoding format -
call it the ZlotnikiType - and he might use, as a matter of convenience,
the HDF5 storage format, that is represented as a file. These relationships
are tracked, and permit discovery of what tools can operate against
what objects. In this way a user may ask what tools exist that can
be applied to a particular data object, from highly specialized
tools that operate against a specific type, for example, the ZlotnickiType,
to general-purpose tools such as those that manipulate files. Or
perhaps the user wants to know what scientific functions may be
applied. This too is an easy query; It's a robust environment when
the associations are clear.
In
short, we believe relationships are among the very most important
features in any interoperability system. Our system has just the
right architecture for managing all relevant relationships within
an Earth Science framework; one is not compelled to provide all
these relationships when they are not available, though there is
a place for them when they are.
User interfaces
Implementation
& Extensibility - Web Browsers, Java applications, Z39.50, search
engines, etc:
As stated
above, we plan to provide at least four forms of access: a pure HTML-based
"application," a more traditional stateful application written in
Java, a Java API, and direct connections to the database (for sophisticated
users with their own ODBC or JDBC tools). In our view, these four
are sufficient to provide robust access and excellent extensibility.
We have no illusion that the funding requested in our modest proposal
is sufficient to create a general -purpose application and web page
that will meet everyone's hopes and dreams. Yet, we can do justice
to the task, and our offering of an API and direct connections allows
others to implement their own visions. Given dialogues with fellow
ESIP Members, we have reason to believe that others are interested
in doing so.
In addition,
at the time of this writing, we are working in conjunction with our
fellow ESIP partner Dr. Konstantinos Kalpakis (USRA ESIP), to expand
our system's capabilities to provide Z39.50 and XML servers.
Local
extensibility -
Attributes,
Vocabularies, Search capabilities, Retrieval capabilities, Data access,
Provision
of access to local extensions:
The
BigSur Earth Science System®
has a whole section dedicated to the management of tools available
at various sites, including the types of objects against which they
operate, where to find them, and even how to start them. Thus, there
is robust access to such features. We have discussed above extensions
for attributes, and they are sufficient so long as we are not referring
to a general-purpose browsing (searching) application that has full
knowledge thereof. Since we provide direct database access, there
is good extensibility for attributes, search & retrieval capabilities,
and also data access through use of local tools. So, we provide robust
access to local extensions.
Technology
Portability
- Platform dependencies
Our
HTML application will have the widest audience we can imagine. Our
Java application should enjoy similar platform independence, as
will our other tools, since most platforms have ODBC and JDBC tools
by this date.
The
database can reside on any system which provides an "industrial
strength" RDBMS, though our preferred vendor is Informix, for cost
and technical capability reasons. (Informix has a very wide range
of platforms available.) Should the Federation not wish to use Informix,
we can easily port our work, though it will mean some delay in delivery.
Implementation
- Language, Special communication requirements (persistent connections,
non-standard ports and/or protocols, interactions with firewalls):
As
outlined above, our applications will be written in HTML, and Java,
with SQL for database access. We may offer Z39.50 and XML services.
We
have no unique communications requirements beyond normal Internet
connectivity. Our HTML application will not use persistent connections,
while our Java application will. Our system will not have any trouble
with firewalls unless the Federation wishes to put the database
engine behind one. We do not envision the use of non-standard protocols.
Scalability
/ Bottlenecks
- Number
of providers - We
presume here that we are to discuss where the database platform will
reside and how it might scale with a workload. Our system has the powerful
ability to be split and divided at will because elements in our database
such as objects and tools all have location information as a part of
their meta-data. The only challenge here is in coordinating applications,
directing them to appropriate servers. To aid this, our database design
already incorporates the meta-data to direct clients to specific database
engines available on any network. We will provide a methodology whereby
interested applications contact a central site, and may be directed
to alternative sites for more in-depth queries.
By providing the
capability to redirect applications to alternative servers, a host
of benefits accrue, including: fault-tolerance, a no-downtime backup
capability, bottleneck avoidance, and the ability to take advantage
of distributed compute and storage resources.
- Number
of users - Because
Informix, our preferred RDBMS vendor, utilizes a multi-threaded, multi-server
architecture, the system is very efficient at managing user connections.
It is nearly certain that the system would experience a bottle-neck
elsewhere long before a limit on the number of users would be exceeded.
However, if we should discover bottlenecks or otherwise have sufficient
load to warrant it, we can divide the system and overcome such problems.
- Volume
of data -
We believe the scale of the Informix RDBMS 's storage ability
is somewhere beyond ten terabytes. It would take an exceptionally large
collection of meta-data to exceed such capacity! We are far more likely
to outstrip the Federation's budget for disk drives! However, given
our ability to split the environment, we may be able to take advantage
of available resources scattered about. We can say that our database
schema is well normalized, and has been de-normalized purely for performance
and usage considerations. In addition, our proposal provides for a large
number of Gigabytes of disk storage (from both JPL and Berkeley Earth
Science Tools) which should be more than sufficient for the duration
of this funding cycle.
-
Performance
As of
the spring of 1999, benchmark reports suggest that Informix, our preferred
RDBMS vendor, has a substantial lead over other RDBMS providers in
scalability and raw performance. (It also has the most sophisticated
and highest performing Object-Relational model.) We expect our system
to have robust performance, even when filled with a large quantity
of meta-data, and with a heavy user-demand.
- Rates
No statistics
have been provided or suggested by the Federation for determining
rates of access - this is an unknown. However, the systems we will
use are of relatively high capacity, and we have several of them available,
so we are not concerned about this at this time. We would be delighted
to have sufficient interest by the public to experience a problem
with access rates!
- Latencies
Similarly,
no scale information has been provided or suggested by the Federation
for use in determining load and therefore what latencies might exist
in a deployed system. For a database system, other factors beyond
just the scale of information to be searched determine search result
latencies; schema design and indices are crucial. We know our database
design is well normalized for elimination of redundancy, has been
de-normalized for performance, is well organized into logical groupings,
and has the world's fastest geo-spatial indexing methods at its disposal.
This system will outperform any similarly-sized computer whose data
organization is monolithic or which does not have R-Tree spatial indexing.
And, by helping users ask better questions, performance will be further
improved, reducing latency.
- Differential
degradation of capabilities
We do
not anticipate any differential degradation of capabilities as scale
increases because we have taken careful measures to address performance
considerations. This is not to say that some user queries might consistently
outperform others, or that as the database grows in size, some queries
remain fast while others become slower. This is normal. We are prepared
to handle this eventuality, because we have a well designed strategy
for overcoming bottlenecks.
- Fault
tolerance
Our architecture
is among the most fault-tolerant possible. Starting with a fully distributed
architecture, and an application capable of connecting to alternative
sites, the only single point of failure possible is the "master" site
and its database. Our plan to address this is to provide a backup
system, which is kept up to date all the time and to teach the applications
to visit the second site should the first be unreachable. Thus, fail-over
is quick and simple. We will also use the second site for a full-sized
development and testing environment, and perhaps occasionally to provide
additional capacity.
Costs
- Distribution
of costs to Providers (minimal vs. optional) and the Federation (Type
3s?)
Most
of the costs of this proposal will be borne by the Proposers. "External"
costs borne by ESIP Members who create data sets - "Providers" - will
be related to the minimum obligations they must fulfill without regard
to our system. Those that wish to do more are encouraged to have a
liaison spend some time with a member of our team to help implement
superior data-gathering tools to automate this aspect of our mutual
interest. We are willing to take as much of this burden upon ourselves
as limited funding and competing goals allow.
In addition,
we have interviewed a number of Type 3 ESIPs. In some cases the burden
they pose is so modest we realize it is in our mutual interest to
take on the task of managing a Type 3's meta-data ourselves. This
may not be true of all Type 3s, but we anticipate that for those that
have computer systems where internet access to meta-data can be made
available, we can work with them to gather it easily. For those that
do not, the quantity of meta-data is sufficiently small that the burden
it poses falls into the "noise" category as compared to other, larger
sites.
- Remaining
costs: "plug-in" (purchase, construction, and configuration),
administration, and maintenance.
Our proposal's
request for funds will cover all necessary costs for implementation
of our system. We will not purchase any computer equipment with these
funds. Rather, existing resources will be provided for the duration
of this funding cycle. These resources include compute hardware, licenses,
administration, and maintenance, as outlined above.
It should
be noted that our proposal requests, but does not insist, that the
Federation provide the hosting of at least the central installation
of our system on the computers that the Federation is using to host
its web-site. This is sensible both from both business and technical
perspectives. We realize that the selection of the web-site host neither
anticipated nor included funding explicitly for this purpose. Because
of the flexibility of our system, we can implement it either way,
and are happy to work with the web-site provider to further these
Federation goals.
Compatibility
- Strategy for accommodating existing systems/clusters/protocols
As stated
in myriad ways above, our system is compatible with and is a complement
to other systems offered by singular sites or clusters. We will write
some code here and there to aid the transfer and interchange of meta-data,
with the goal of automating such transfers. In particular, we will write
code to fetch GCMD meta-data and deposit into our database system, and
take data from our system and supply it to GCMD. And we are partnering
with a number of other ESIPs to further our mutual goals in these areas.
[end of document]
|