| Copyright © 1997 - 2026 Science Tools Corporation All rights reserved | |
|
|
|
|
The
BigSur System™
Introduction Our BigSur System is the inheritor of the intellectual capital of interdisciplinary global-change research dating from the 1992 Sequoia 2000 Project, and subsequent 1995 BigSur Project at the University of California, Berkeley, and includes the insights of Turing Award winner Jim Gray, and world renown Professor Michael Stonebraker, among other great minds. Add to the mix the transition from University prototype to real-world product at the hands of a veteran of the computer industry of (at the time) 20 years experience, our own Richard Troy, working in close concert with a major U.S. research center (LaRC), and you have a very capable product. Overview | Perspective | Implementation | Primary Features | Major Components The
Overview
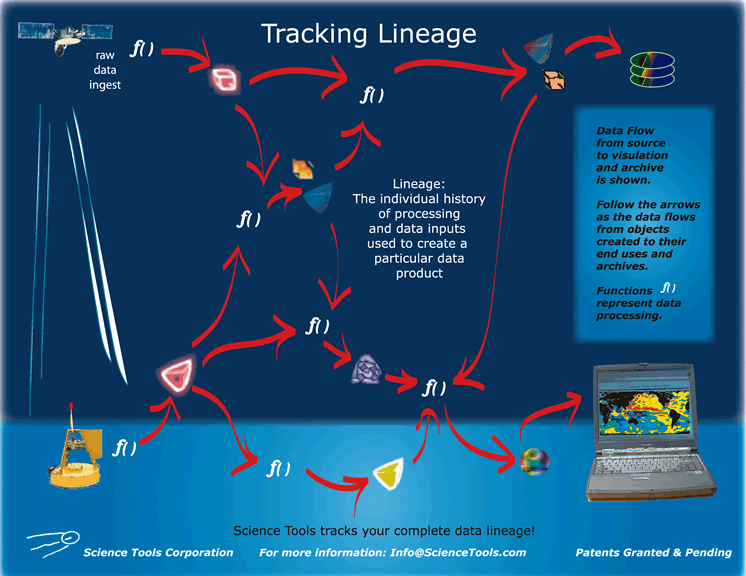
The BigSur System™ implements a science computing environment able to handle the needs of a single researcher, a research site, or an entire research community distributed across the Internet. Science, as an activity, is immersed in the challenge of data-management; BigSur is a general-purpose science system which brings modern database and high performance computing technology to bear on the most difficult challenges in scientific computing. BigSur learns about scientific data-types, the processes that operate against them, the visualization tools and access methods used to view and manipulate them. It learns the structural organization into which scientific data belong, and it manages that organization for its users. BigSur is taught the processing flow of data into and out of scientific processes and can then automate that processing. BigSur records the relationships as new scientific objects are created and retains the lineage and associations between them and their processes. The entire history of objects are therefore known, and this information can be used to create new objects when older data are superseded.
(click
for larger image) BigSur knows about more than just scientific objects. It also knows about your compute resources, where you want processing performed, and can cite your documents and web links as references to your data objects. If you teach it, it knows about people and teams with whom you collaborate, what software tools they use, what scientific processes they have and what data-types those processes can operate on. It can publish your work to their systems if you wish, cause their processes to be executed, and can use and reference their data-products as inputs to your own scientific processes - all at the control of the investigators in charge and with the permissions they may or may not grant, of course. Best of all, it can "encapsulate" existing environs whole, as is, without changing their fundamentals. And where few resources are available, it can act in a more limited mode and provide many of these features without need for full implementation on the part of your collaborators.
Perspective Among the challenges of performing Science in the modern era, perhaps the most ignored is management of the big picture. Most researchers already have favorite or discipline specific data-types and visualization tools, but are woefully lacking in management of the meta-data -- the data about the data. Most often this meta-data is held in the brains of researchers and graduate students, and sometimes in notebooks, and is nearly never available online. It needs to be recorded and available in a common repository. If sufficient meta-data is managed in a system, it provides an opportunity for automation and standardization of methods of access and processing. We believe that a Science System needs to be flexible and learn the paradigms, data-types and functions (processes) of researchers, rather than the other way around. And we believe that the system must be as 'light weight' and trim as is possible - the less there is to learn and mess with the better, so long as it is functional. The functionality domain is literally from data source (eg: sensors) to end-users desk-top - the furthest "end to end" possible. Of course, many, maybe most users won't want or need to reach all the way to each end, but we feel it is imperative to handle such breadth - it is far easier to ignore features you don't need than try to add them later. Implementation The BigSur System™ is made up of a collection of core components. Central to this collection is the Science-Tools Database (STDB), which is further extensible for work in specific disciplines. Our Geo, and Med extensions to STDB provide Geographic and Medical Record capababilities, respectively. For the execution of Scientific Processes, the Distributed Processing System (DPS) provides the framework - BigSur's DPS is the world's first true grid computing platform. It, in turn, consists of a number of components, including both a Demand Engine (DPS-DE) which initiates processing when requested to do so, and an Eager Engine (DPS-EE) which initiates processing when parental data products become available. The system depends upon a Relational Database Management System (RDBMS). To expedite access to the database in an appropriate way, and to enforce security and ensure the system behaves as expected, several management applications are provided as well as a large, sophisticated Application Programming Interface (API), which at the time of this writing, contains not less than 1646 functions (methods). Generally, customers only need to write code for two basic purposes to meet their specific needs: 1) "Scientific Processes" (or functions) are and will always remain the responsiblilty of the researcher - you need to know what your science is! - and; 2) Customers often wish to have very specific interfaces for their users and/or customers. In both cases, we are expert at helping you make such implementations as you desire, and we offer a suite of services to help you reach your goals. In addition, we offer templates to get your started off on the right foot.
Primary Features Many features can be used independently of the others, while some are dependent and build upon the abilities offered by others.
Major Components
|
|
| Feedback |
website contact: Webmistress |